11
11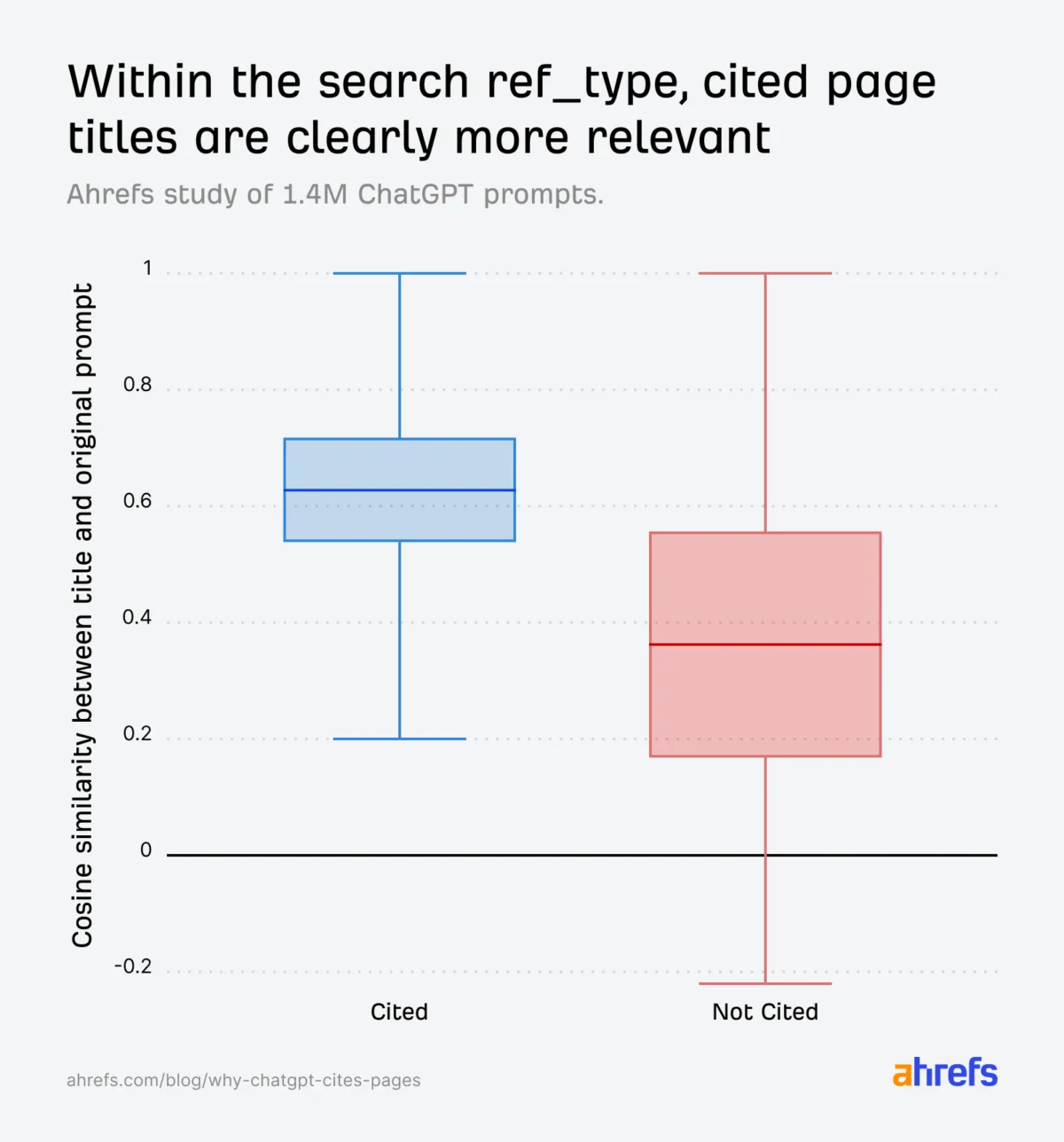
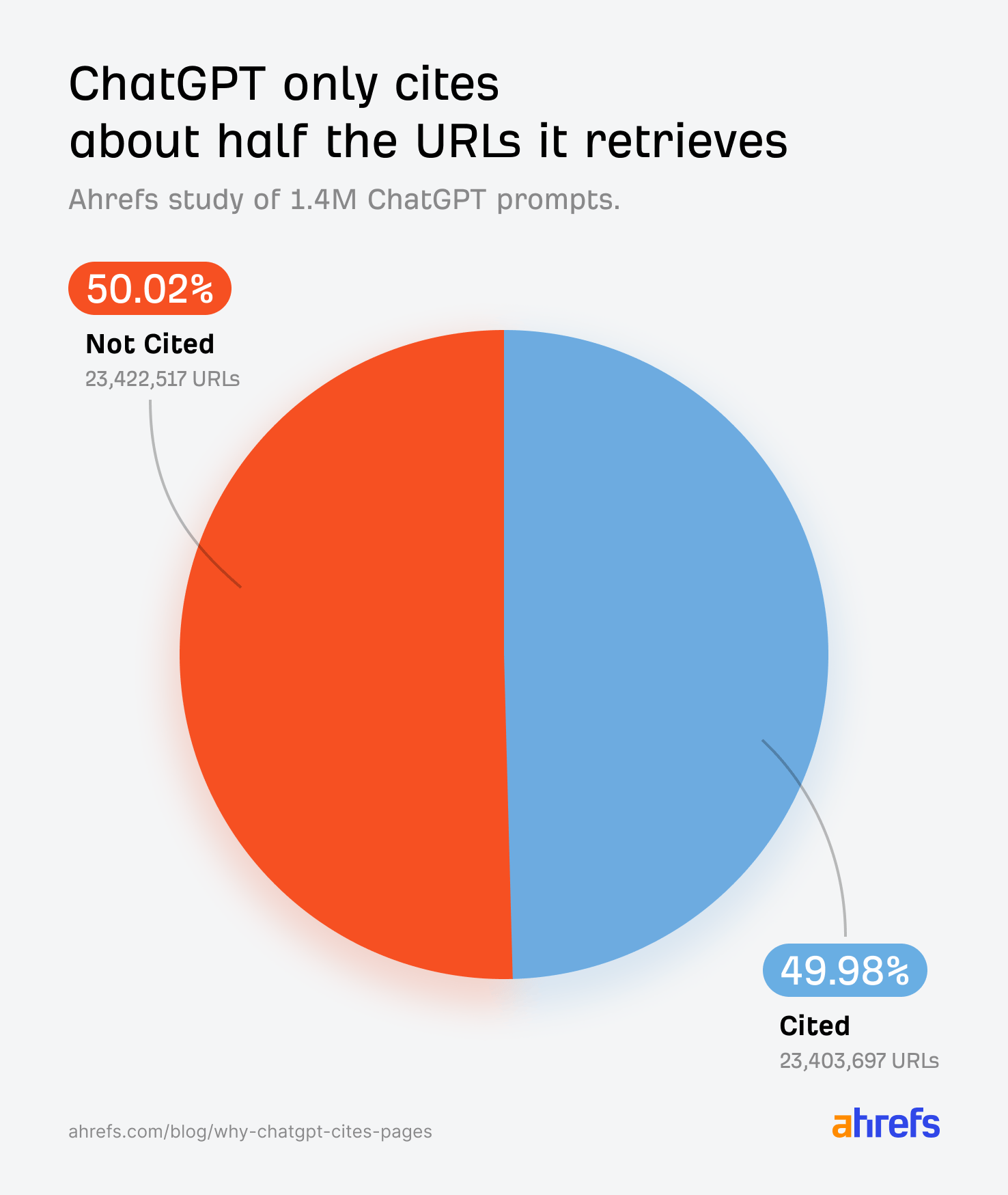
A comprehensive analysis of 1.4 million ChatGPT prompts, conducted by Ahrefs with data scientist Xibeijia Guan, has uncovered that the popular AI chatbot cites only about 50% of the web pages it retrieves to answer user queries. This research delves into the factors influencing which sources ChatGPT ultimately credits, offering crucial insights for content creators aiming for visibility in AI-generated responses.

The familiar numbered blue links in ChatGPT’s responses serve as citations, backing up its generated text with external information. However, despite retrieving dozens of URLs for a single query, the AI selects only roughly half of them for citation. This selectivity raises the question: what determines which page gets the credit and which is overlooked?
According to studies by AI expert Dan Petrovic, ChatGPT retrieves search results along with their titles, snippets, URLs, and ID numbers. This metadata forms an initial "gatekeeping layer" that ChatGPT uses to decide which pages are worth further investigation and potential citation, before it even accesses the full content.
The Ahrefs study aimed to identify the specific factors influencing this citation process. Researchers investigated whether semantic similarity between a page’s retrieval data and the user’s query increases the likelihood of citation, which fields are most influential, and whether human-readable URLs perform better.
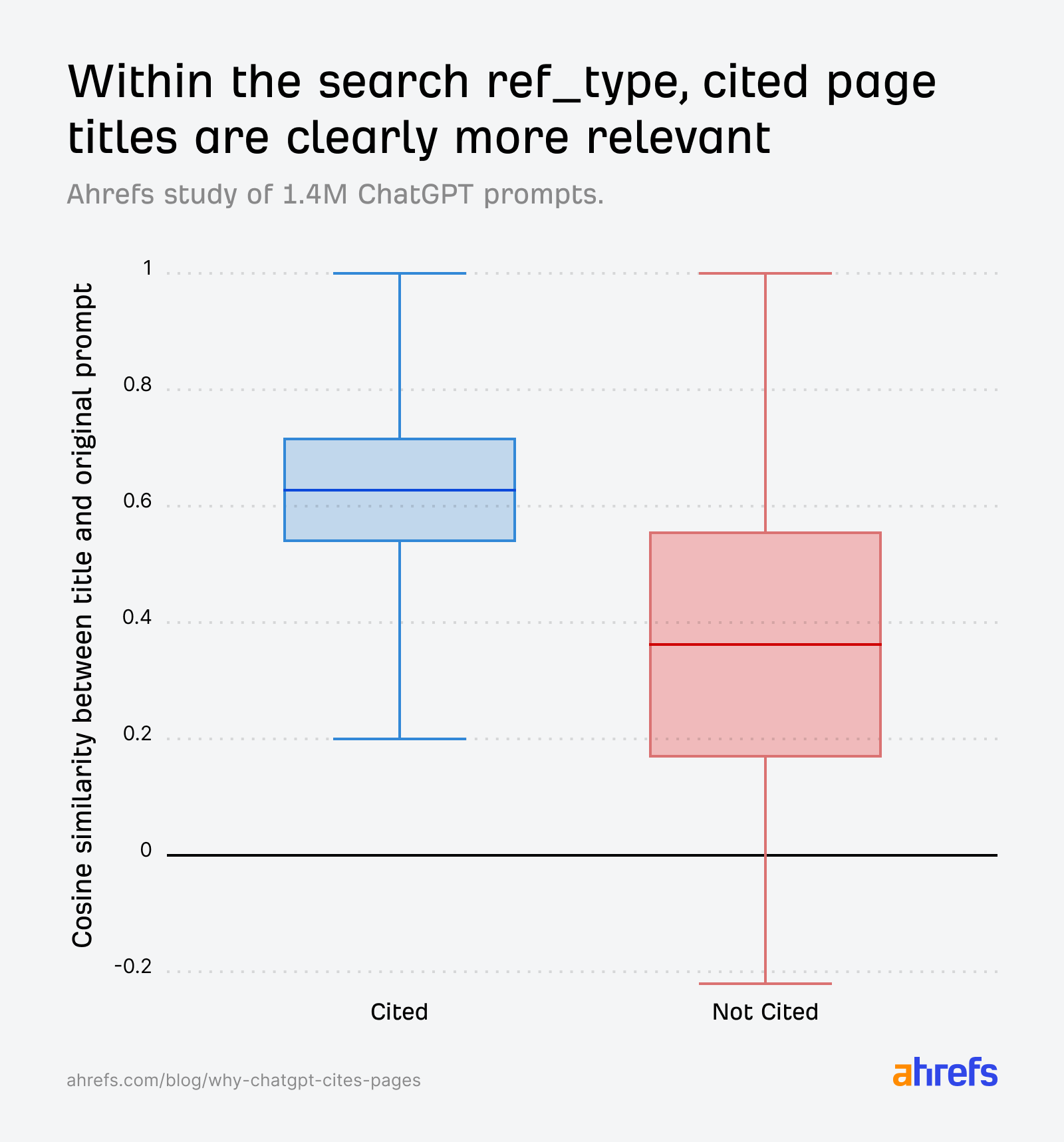
A key finding of the research is the significant disparity in citation rates across different source types, categorized by an internal field called ref_type. ChatGPT categorizes sources into five types: search, news, reddit, youtube, and academia. The citation rates vary dramatically:

The general "search" index overwhelmingly dominates, accounting for the vast majority of cited URLs. This underscores the importance of ranking well in standard search engine results pages (SERPs) to be considered by ChatGPT. Specialized platforms like YouTube and academic repositories are retrieved in large volumes but are rarely cited.
A particularly striking observation is the role of Reddit. While Reddit comprises 67.8% of all non-cited URLs, it has its own dedicated ref_type with over 16 million data points in the study. The low citation rate of 1.93% suggests that ChatGPT extensively uses Reddit for understanding topics, gauging consensus, and building context, but rarely attributes this information directly to Reddit sources. The AI appears to learn from the collective knowledge on Reddit but cites other institutions.
The research also examined the influence of populated fields within ChatGPT’s retrieval data, such as snippets and publication dates. Initially, non-cited pages seemed to have more populated fields than cited ones. However, this discrepancy was largely attributed to the overwhelming presence of Reddit data in the non-cited pool. Reddit content, often pulled via API, naturally includes metadata like publication dates, skewing the aggregate numbers.
Further analysis, isolating the "search" ref_type, revealed a clearer picture. Snippet data proved to be largely absent for both cited and non-cited search results, indicating it’s not a reliable signal for citation. Publication dates showed closer percentages, but the data did not allow for strong conclusions about their meaningful role in citation. The study cautions that aggregate comparisons without accounting for ref_type can lead to misinterpretations.
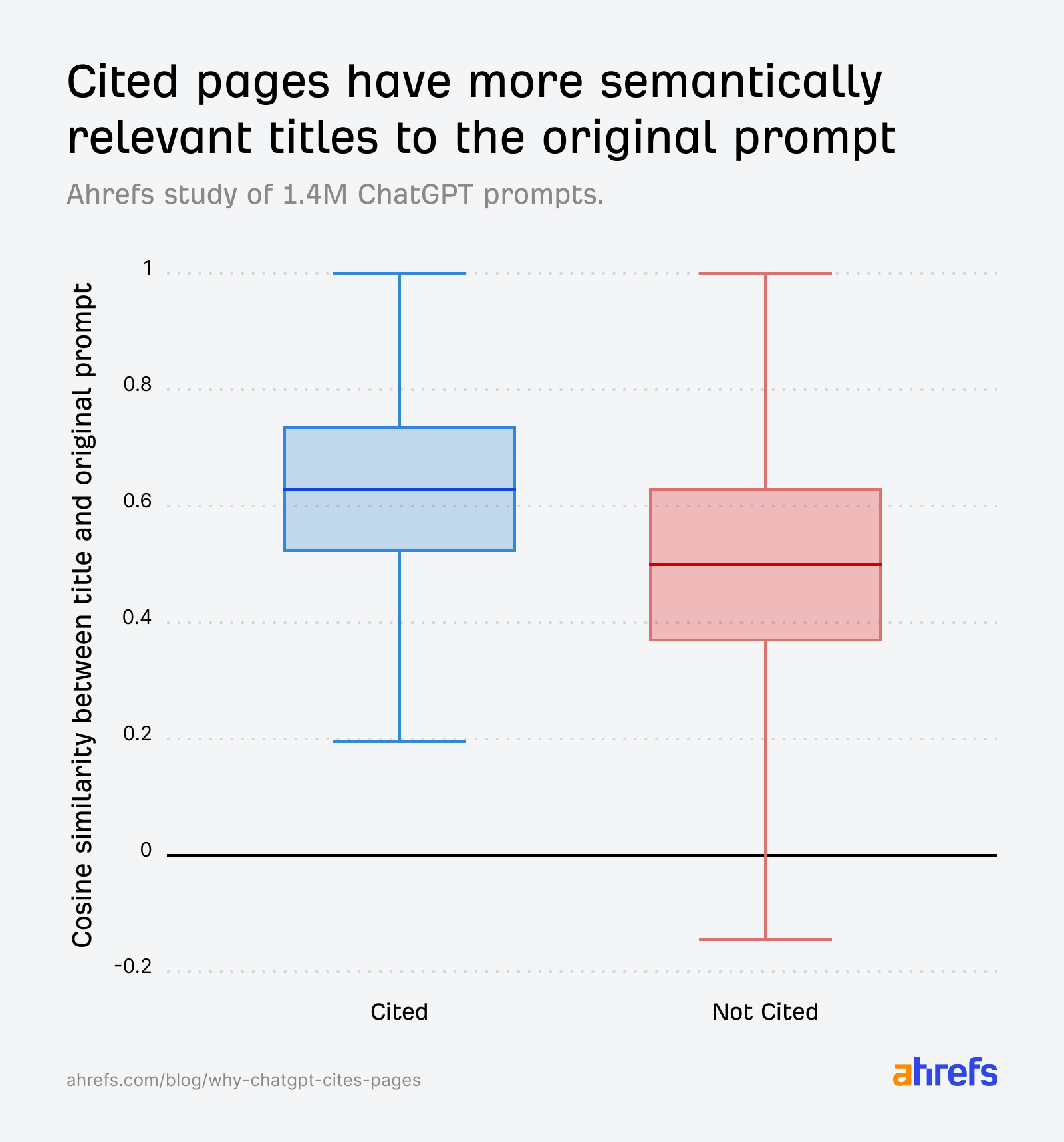
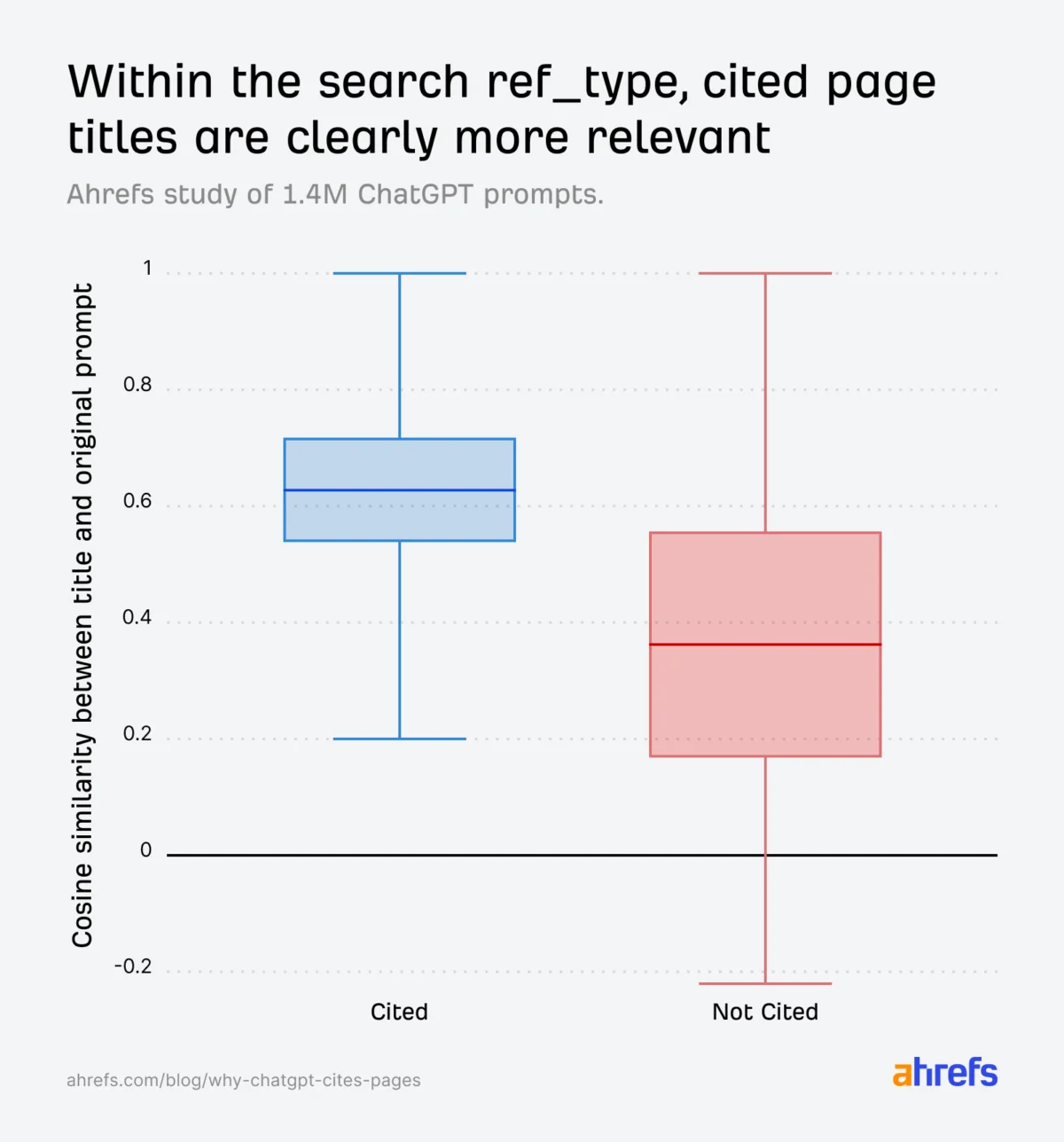
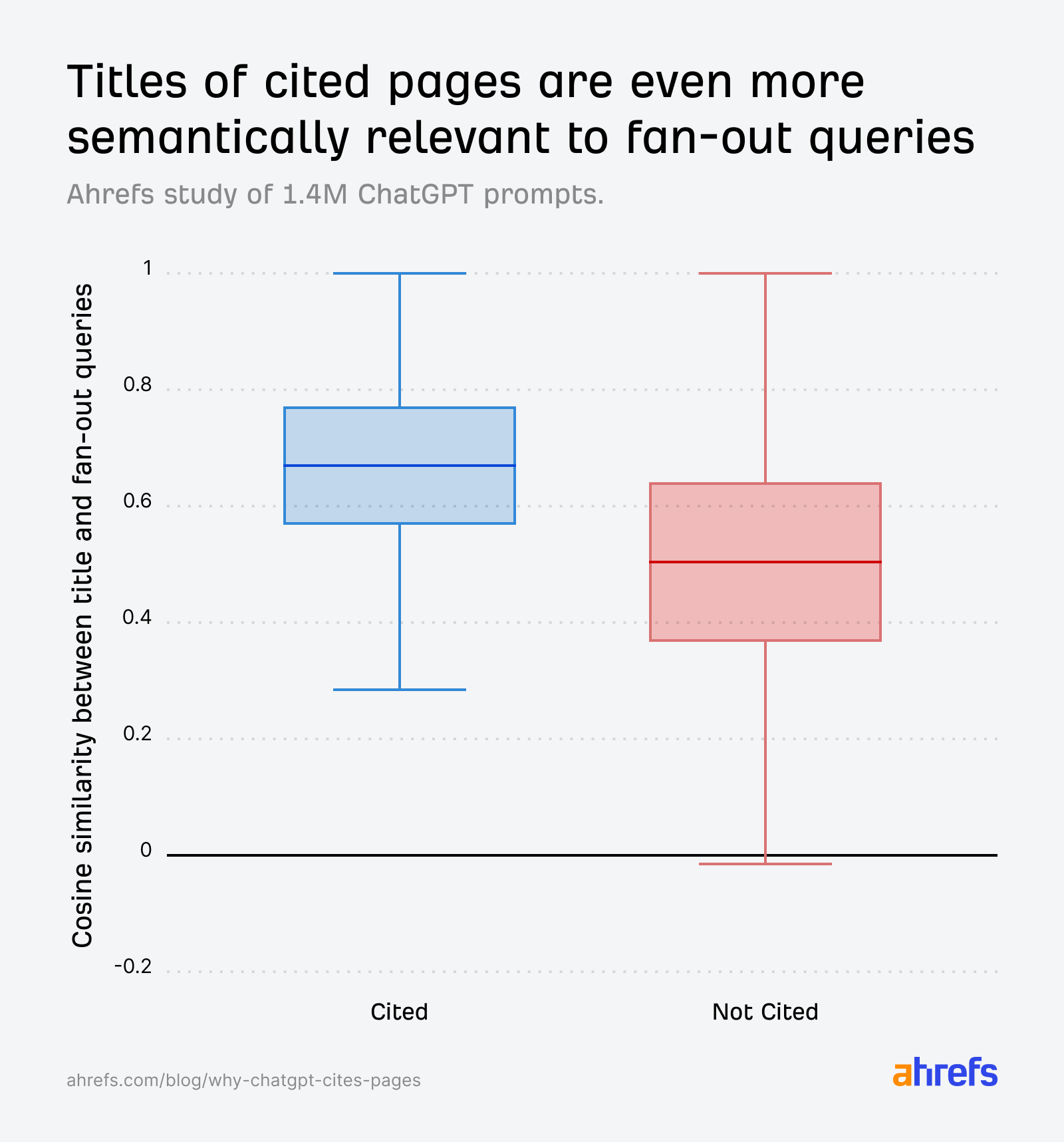
Semantic relevance emerged as a critical factor for citation. ChatGPT employs a process akin to "semantic scoring" to determine if a retrieved article aligns with a user’s query. By using cosine similarity computed from embeddings of open-source models, researchers approximated ChatGPT’s relevance estimation. The data confirmed that titles semantically aligned with ChatGPT’s internal "fanout queries" (sub-questions generated by the AI) significantly increase citation likelihood. Cited URLs consistently showed higher similarity scores between their titles and the original prompts, and even more so with fanout queries.
The study also noted that search results with natural language URL slugs had a higher citation rate (89.78%) compared to those without (81.11%). Ultimately, content whose URL and title semantically align with the AI’s internal queries is more likely to be cited.
Regarding content age, while AI assistants are generally known to prefer fresher content, the research offered a nuanced view. In the "search" index, cited pages spanned a wide age range, with a median of approximately 500 days. Interestingly, non-cited pages were predominantly very young. This suggests that within a given retrieval set, relevance outweighs freshness. A new page that strongly matches fanout queries will be cited, while a new page that doesn’t will be retrieved but ignored.
However, for "news" queries, freshness becomes a more decisive factor. When title relevance scores were nearly identical between cited and non-cited news articles, the AI defaulted to page age as a tie-breaker. Cited news pages tended to be younger, with a median age of around 200 days, compared to non-cited pages at roughly 300 days.
In conclusion, the research indicates that ChatGPT prioritizes content from its general search index, leverages semantic similarity for source selection, and heavily relies on titles and content that align with its internal sub-queries. The findings highlight the importance of optimizing content for relevance and understanding the distinct retrieval and citation mechanisms for different source types.