 11
11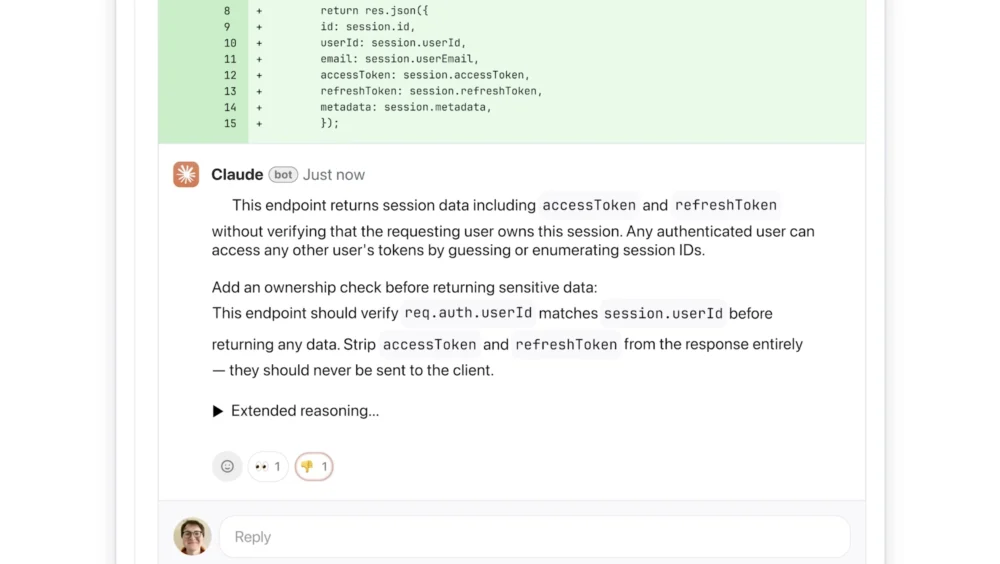
In the rapidly evolving landscape of software development, the role of peer feedback remains paramount. This human-centric review process is indispensable for the early detection of bugs, ensuring consistency across vast and complex codebases, and ultimately elevating the overall quality and reliability of software products. However, the advent of "vibe coding"—a revolutionary approach leveraging artificial intelligence tools to generate extensive code from plain language instructions—has profoundly reshaped the daily workflows of developers. While these sophisticated AI tools have undeniably accelerated development cycles, they have simultaneously introduced a new array of challenges, including novel bugs, unforeseen security vulnerabilities, and large volumes of code that are often poorly understood by human developers, necessitating more rigorous and efficient review mechanisms.
Responding directly to these emerging complexities, Anthropic, a prominent AI research and safety company, has unveiled its innovative solution: an AI reviewer meticulously designed to identify and flag potential issues within code before they are integrated into the main software codebase. This groundbreaking product, aptly named Code Review, made its official debut on Monday, integrated seamlessly into Anthropic’s existing Claude Code platform. The launch marks a significant step in addressing the bottlenecks created by the very efficiency gains offered by AI-generated code.
Cat Wu, Anthropic’s head of product, articulated the driving force behind this new offering in an interview with TechCrunch. "We’ve seen a lot of growth in Claude Code, especially within the enterprise, and one of the questions that we keep getting from enterprise leaders is: Now that Claude Code is putting up a bunch of pull requests, how do I make sure that those get reviewed in an efficient manner?" Wu explained. Her statement underscores a critical pain point for enterprises adopting AI coding assistants: the sheer volume of new code, while a boon for speed, translates into an equally overwhelming volume of review tasks.
Pull requests, a standard and critical mechanism in software development, serve as a formal gateway for developers to propose code changes for scrutiny by their peers or automated systems before these modifications are merged into the live software. Wu highlighted that Claude Code’s remarkable ability to dramatically increase code output has, in turn, led to an exponential surge in these pull requests. This surge has inadvertently created a significant bottleneck in the development pipeline, impeding the swift and continuous deployment of new software features and updates. "Code Review is our answer to that," Wu affirmed, positioning the new tool as a direct solution to this pressing operational challenge.
The introduction of Code Review, initially made available to Claude for Teams and Claude for Enterprise customers as a research preview, arrives at a particularly pivotal juncture for Anthropic. The company recently found itself embroiled in a legal dispute, filing two lawsuits against the Department of Defense (DoD) on Monday. These lawsuits were a direct response to the agency’s controversial designation of Anthropic as a "supply chain risk." This ongoing dispute is likely to compel Anthropic to lean more heavily on the robust performance and continued expansion of its burgeoning enterprise business, which has witnessed an impressive quadrupling of subscriptions since the beginning of the year. Furthermore, Claude Code, the platform into which the new Code Review tool is integrated, has already achieved a remarkable run-rate revenue exceeding $2.5 billion since its launch, according to figures released by the company. These financial and strategic indicators underscore the growing importance of enterprise solutions and the potential impact of Code Review on Anthropic’s market position.
Wu further elaborated on the specific target demographic for Code Review, emphasizing its focus on large-scale enterprise users. "This product is very much targeted towards our larger scale enterprise users, so companies like Uber, Salesforce, Accenture, who already use Claude Code and now want help with the sheer amount of [pull requests] that it’s helping produce," she stated. These prominent organizations, characterized by their extensive development teams and complex software ecosystems, are precisely the entities that stand to gain the most from an automated, intelligent code review assistant capable of handling high volumes of AI-generated code.
A key aspect of Code Review’s functionality is its ease of integration and deployment within existing developer workflows. Developer leads within an organization can activate Code Review to operate as a default setting for every engineer on their team. Once enabled, the tool seamlessly integrates with GitHub, one of the most widely used platforms for version control and collaborative software development. This integration allows Code Review to automatically analyze incoming pull requests, meticulously scanning for potential issues. Upon identifying problems, the AI reviewer leaves contextual comments directly on the relevant lines of code, providing clear explanations of potential issues and offering actionable suggestions for remediation.
Crucially, Wu highlighted a strategic design decision that differentiates Code Review from many other automated feedback systems: its singular focus on identifying and rectifying logical errors rather than merely suggesting stylistic improvements. "This is really important because a lot of developers have seen AI automated feedback before, and they get annoyed when it’s not immediately actionable," Wu explained. Traditional linters or basic AI tools often flag minor style discrepancies, which, while sometimes useful, can frequently be perceived as low-priority noise by busy developers. "We decided we’re going to focus purely on logic errors. This way we’re catching the highest priority things to fix," she added, emphasizing the tool’s commitment to delivering impactful and immediately actionable insights.
The AI’s feedback mechanism is designed for transparency and clarity. When an issue is detected, the system provides a step-by-step explanation of its reasoning, articulating what it perceives the problem to be, why it might be problematic in the context of the larger codebase, and how it can potentially be resolved. To aid developers in prioritizing their work, Code Review employs a color-coded severity labeling system. Issues deemed of the highest severity, demanding immediate attention, are marked in red. Potential problems that warrant careful review, though not necessarily critical, are highlighted in yellow. Furthermore, the system includes a unique purple label for issues that are tied to pre-existing code or historical bugs, providing valuable context and helping developers understand if a new change is interacting with legacy issues.
Wu further shed light on the sophisticated architecture underpinning Code Review’s efficacy. The tool achieves its speed and thoroughness by relying on a multi-agent system, where multiple AI agents operate in parallel. Each agent is tasked with examining the codebase from a distinct perspective or dimension, ensuring a comprehensive analysis. A final, aggregating agent then synthesizes and ranks the findings from all individual agents, intelligently removing duplicate reports and prioritizing the most critical issues to present a concise and actionable summary to the developer.
While Code Review offers a light security analysis as part of its comprehensive review, engineering leads have the flexibility to customize additional checks based on their organization’s internal best practices and security policies. For more in-depth and specialized security scrutiny, Wu pointed to Anthropic’s more recently launched Claude Code Security, which is specifically designed to provide a deeper and more exhaustive security analysis of codebases. This modular approach allows enterprises to tailor their AI-driven code quality and security measures to their specific needs.
The sophisticated multi-agent architecture, while powerful, does imply that Code Review can be a resource-intensive product, as acknowledged by Wu. Similar to other advanced AI services, its pricing model is token-based, meaning the cost of a review fluctuates depending on the complexity and volume of the code being analyzed. Wu provided an estimated cost range, suggesting that each review would typically cost between $15 and $25 on average. She framed this as a "premium experience," but also a "necessary one" in an era where AI tools are generating an ever-increasing deluge of code. The cost, therefore, is positioned as an investment in quality and efficiency, mitigating the hidden costs associated with undetected bugs and slow review cycles.
Wu concluded by underscoring the strong market demand that fueled the development of Code Review. "[Code Review] is something that’s coming from an insane amount of market pull," she stated, highlighting that as engineers increasingly leverage Claude Code for accelerated development, they are simultaneously experiencing a significant reduction in the friction associated with creating new features. This increased velocity, however, has translated into a commensurately higher demand for code review, creating the very bottleneck Code Review aims to alleviate. "So we’re hopeful that with this, we’ll enable enterprises to build faster than they ever could before, and with much fewer bugs than they ever had before," Wu expressed, articulating Anthropic’s vision for a future where AI not only accelerates code generation but also elevates its quality and security through intelligent, automated review.
The launch of Code Review is a testament to Anthropic’s strategic commitment to supporting enterprise clients navigating the complexities of AI-powered development. By addressing a critical bottleneck in the software development lifecycle, Anthropic aims to solidify its position as a leader in providing comprehensive AI solutions that enhance both the speed and reliability of modern coding practices. The tool’s integration into GitHub, its focus on logical errors, multi-agent architecture, and tiered severity labeling system collectively represent a significant advancement in automated code quality assurance, promising a future of faster, more secure, and higher-quality software delivery for its enterprise users.
Rebecca Bellan is a senior reporter at TechCrunch, specializing in the business, policy, and emerging trends shaping artificial intelligence. Her extensive journalistic background includes contributions to Forbes, Bloomberg, The Atlantic, and The Daily Beast, among other notable publications. Rebecca can be contacted for inquiries or verification of outreach via email at [email protected] or through encrypted message at rebeccabellan.491 on Signal.




