
Atlassian Scales Jira Migration Platform to Support 50,000-User Enterprise Environments
The Atlassian Jira Migrations team has completed a year-long technical evolution, successfully scaling its migration platform from supporting 20,000-user environments to reliably handling 50,000-user migrations. This transition marks a critical milestone in Atlassian’s broader strategy to transition its customer base from Data Center (DC) deployments to the Cloud, particularly following the company’s recent announcement regarding the end-of-life for Jira Data Center. In the context of enterprise software, a "50K-scale" organization typically refers to a Monthly Paid Enabled User (PEU) count of approximately 50,000, representing a massive operational footprint that encompasses thousands of individual projects and millions of discrete work items.

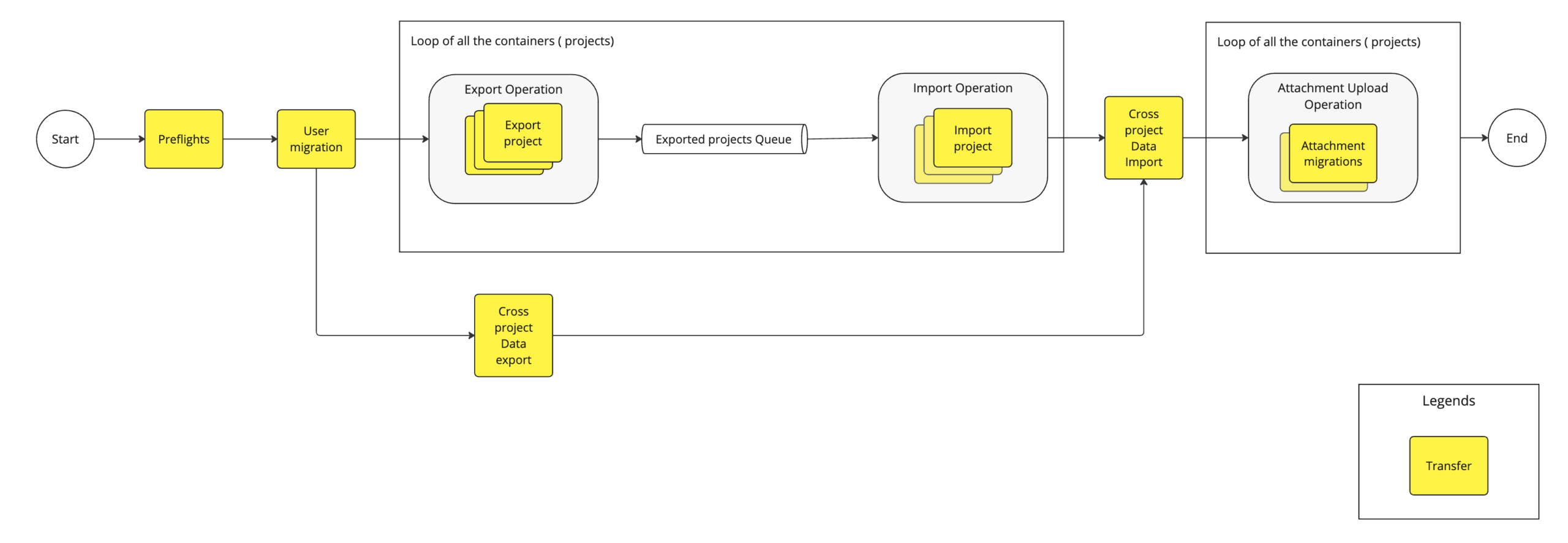
The migration of such vast datasets is a complex undertaking, as Atlassian’s cloud environment requires new data to be integrated seamlessly with existing user activity and historical records. Because of this requirement, simple database overrides are not an option. Instead, the team utilizes the Jira Cloud Migration Assistant (JCMA), which employs a project-based migration strategy. In this model, data is exported from the Data Center environment and subsequently imported into the Cloud destination.
Previously, the migration pipeline relied on what is known as a "V3" architecture. This was an API-driven, push-based model. Under this system, the migration process involved identifying entities for migration, exporting them into files, and then making sequential API calls to create those entities in the Cloud. While functional for smaller organizations, this architecture proved to be a significant bottleneck for enterprise-scale customers. The push-based model made it difficult to balance throughput without overloading the target system, and the architecture suffered from "N+1" query issues, where the system made excessive network calls for individual items rather than processing them in bulk. Furthermore, the blocking nature of the API calls meant that any slowdown in the target system would immediately halt the migration pipeline.

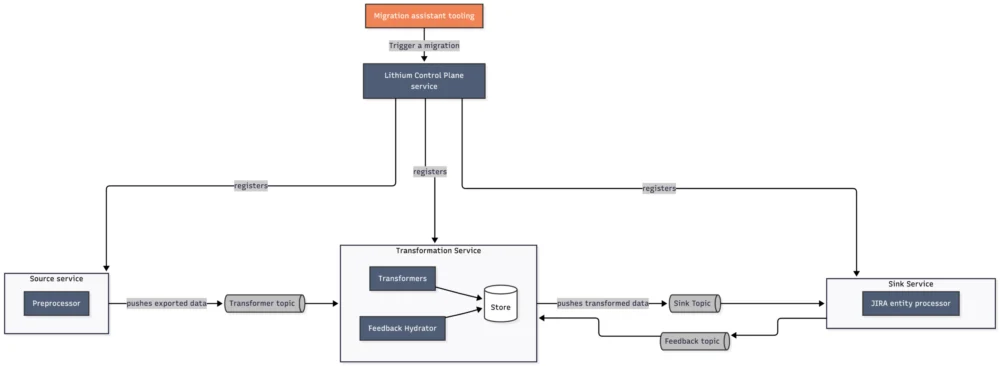
To overcome these limitations, the migration platform team developed the "V4" architecture. This new system shifted to a pull-based model, allowing the target system to maintain control over throughput and scale more effectively without the risk of system overload. The V4 architecture is built on Lithium, an in-house, Kafka-based ETL (Extract, Transform, Load) tool designed for distributed, ephemeral streaming pipelines. The workflow in V4 involves the JCMA exporting data to an S3 bucket, an Orchestrator service managing the migration DAG (Directed Acyclic Graph), and Lithium worker nodes pulling data from the messaging backbone to process and import it into the Cloud database.
Despite the theoretical advantages of the V4 architecture, its initial deployment to 20,000-scale customers revealed unexpected performance issues. Early benchmarks showed that the modern ETL-style pipeline was actually slower than the older V3 model. For large enterprises, this lack of speed was unacceptable. The engineering team treated these performance gaps as a high-priority incident, conducting deep-dive analyses into entity-level throughput and migration timelines.
The first wave of optimizations for the 20,000-scale benchmark focused on infrastructure and concurrency. The team moved from small worker nodes to larger, vertically scaled configurations, finding an optimal balance between cost and performance. They also implemented aggressive autoscaling rules to ensure that worker nodes were provisioned the moment CPU usage spiked, maintaining high throughput from the start of the process. To improve parallelism, the team increased the number of projects that could be imported simultaneously and the number of processors per project. This required a sophisticated communication loop between the migration tools, the orchestrator, and a service monitoring Aurora RDS metrics to ensure the database remained healthy under the increased load.
Code-level improvements also played a vital role in this first phase. The team moved toward bulk API patterns, replaced redundant database calls with efficient caching mechanisms, and optimized data serialization processes. These efforts resulted in a 6x improvement in median throughput for large, multi-project migrations, giving the team the confidence to move toward the even more ambitious 50,000-scale milestone.

The 50K-scale challenge set a high bar: the system needed to migrate approximately 6,500 projects and 7.5 million work items in under 36 hours, with the import phase specifically restricted to a 24-hour window to minimize downtime for the customer. Achieving this required a four-part strategy focusing on scaling out (concurrency), scaling up (per-project throughput), battle-hardening (stability), and continuous research.
One of the primary issues identified at the 50K scale was slow throughput during the initial startup of a migration. Because the system’s autoscaling was tied to CPU load, and migrations began with an export phase that was less resource-intensive than the import phase, the system remained under-provisioned when the heavy import work actually began. To fix this, the team introduced a proactive provisioning mechanism that ensured a minimum number of worker nodes were operational the moment a large migration was initiated. This adjustment shaved up to 60 minutes off the total migration time and, surprisingly, reduced monthly infrastructure costs by approximately $65,000 USD by allowing for a smaller steady-state footprint.

Another challenge emerged within the messaging layer. As concurrency increased, the high number of Kafka topics and partitions threatened to exhaust the capacity of the messaging clusters. To resolve this, the team implemented "T-Shirt Sized Configurations." Under this logic, projects were categorized by size. Small projects were migrated with minimal overhead, while large projects were granted higher parallelism but were limited in terms of how many could run concurrently. This balanced approach improved migration throughput by 62% and kept infrastructure costs under control by preventing unnecessary Kafka broker scale-ups.
The team also addressed the "long-tail problem," where the total duration of a migration is often dictated by thousands of small projects that finish last due to fixed orchestration overhead. By optimizing the orchestration logic and pruning unnecessary edges in the Directed Acyclic Graph (DAG) of entities, the team reduced the fixed overhead per project by 2 to 2.5 times. They discovered that the system was performing level-order traversals for all entities supported by Jira, rather than just those being migrated. Pruning these "ghost" dependencies saved several hours during large-scale migrations.

The final major hurdle was database replication lag. Under the heavy write load of a 50,000-user migration, the read replicas of the database cluster struggled to keep up, leading to API errors and impacting customer-facing performance. The engineering team implemented a tenant-aware mechanism that routes all reads for a specific organization to the primary database instance during an active migration. Simultaneously, the size of the primary instance is increased to handle the extra load. Additionally, the team optimized the sequence in which projects were migrated to smooth the load over time. These changes reduced replication lag peaks from 60 seconds to just 400 milliseconds, ensuring a stable environment for users even during massive data transfers.
To validate these improvements, the team conducted a certification test using a synthetic dataset designed to mirror the complexity of their largest enterprise customers. The results confirmed that the system could successfully migrate over 6,000 projects in a single day, with the import phase completing well within the 24-hour target.

This journey from 20K to 50K scale demonstrates the compounding effect of technical optimizations in distributed systems. By moving from a push-based to a pull-based architecture and methodically addressing bottlenecks in autoscaling, messaging, orchestration, and database management, Atlassian has fortified its migration platform to support the world’s largest organizations as they transition to the cloud. The project serves as a case study in balancing high-throughput performance with cost-efficiency and system stability at the extreme edge of enterprise software requirements.

