11
11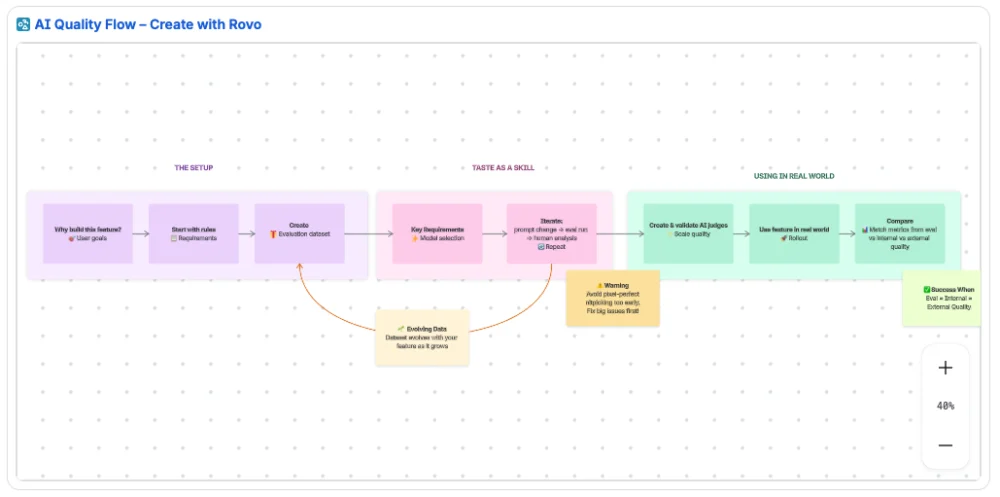
In the rapidly evolving landscape of generative artificial intelligence, the transition from a successful prototype to a production-ready feature remains one of the most significant challenges for product managers. On February 24, 2026, Atlassian released a comprehensive framework based on two years of development within Confluence Whiteboards and the integration of AI-driven capabilities through Rovo. This methodology seeks to replace subjective "vibe-based" assessments with a rigorous, evidence-driven process that ensures AI outputs are consistently reliable for professional delivery workflows.
The core dilemma facing product managers (PMs) today is determining when an AI’s output reaches the threshold of being "good enough" for public release. While "vibes"—a collection of a few positive internal demos and anecdotal successes—might suffice for low-stakes or entertainment-focused AI, they are insufficient for tools that teams rely on for critical business operations. In professional environments, where trust, time, and reputation are at stake, "good enough" must be defined as producing outputs that are consistently useful for the specific task a user intends to perform. This standard is particularly vital when the AI performs complex creative or synthesis tasks, when the output serves as a foundation for further work, or when the cost of a "hallucination" or error is high.
To navigate this complexity, the Atlassian framework outlines a ten-step progression designed to move teams from intuitive feelings to empirical evidence.
The process begins with a strategic foundation: "Starting with the Why." Before a single line of code is written or a prompt is engineered, product teams must answer three fundamental questions regarding customer pain points, the specific opportunity space, and the competitive landscape. This "Why" serves as the anchor for every subsequent quality decision. Once the objective is clear, PMs must translate these requirements into concrete quality rules. These rules form the basis of the "system prompt"—the internal instructions coded into the feature that define the AI’s persona, context, output format, and constraints. Unlike "user prompts," which are free-form requests from the end-user, system prompts act as an encoded product requirements document (PRD) that guides the LLM (Large Language Model) on how to behave, what tone to adopt, and what information to prioritize or ignore.

The third and fourth steps involve the creation and maintenance of an evaluation dataset. A robust dataset is not merely a collection of data; it must be a living manifestation of the feature. It should cover core use cases, include a mix of simple and complex prompts, and mimic the "messy" reality of real-world user behavior. To prevent stagnation, this dataset must evolve as the feature develops. Whenever a new bug is identified, a edge case is discovered, or a model behavior changes, the dataset should be updated. Atlassian recommends maintaining a single source of truth for this data, such as a Confluence database, to ensure version history and accessibility across the engineering and product teams.
Central to this framework is the concept of the PM as the "Benevolent Dictator" of quality. In the context of AI, developing "taste" becomes a critical product skill. The PM must act as the principal domain expert and the final arbiter of quality. This involves a hands-on approach to reviewing outputs, identifying patterns of failure, and making definitive calls on whether an output meets the required standard. This role requires the PM to spend significant time reviewing raw data to ensure that the AI’s "average" performance is high, rather than just its "peak" performance.
The selection of the underlying model family is the sixth critical step. Product teams must navigate trade-offs between speed, cost, and reasoning capabilities. Smaller models may offer lower latency and cost-effectiveness for simple tasks, while larger, more sophisticated models are necessary for complex synthesis. The goal at this stage is exploration rather than perfection; teams must ensure they are using the right "engine" before fine-tuning the specific mechanics of the prompt.
Once a model is selected, the development enters a high-frequency "tight loop" consisting of prompt changes, evaluation runs, and human reviews. This is a collaborative effort where PMs provide daily feedback to engineers. To streamline this process and avoid meeting fatigue, the framework suggests using asynchronous tools like Loom to record recaps of issues and walk through real-world examples of output failures. During this phase, teams should avoid over-indexing on minor "pixel-perfect" details and instead focus on eliminating major behavioral flaws.
As the feature scales toward internal or external rollout, manual review becomes unsustainable. This necessitates the implementation of "AI judges"—LLM-based systems designed to mimic human judgment. These judges can evaluate thousands of outputs for criteria such as relevance, tone, and accuracy while maintaining user privacy by avoiding the need for human eyes on sensitive user-generated content. However, these judges must themselves be validated. A PM should "train" the AI judge by comparing its scores against human scores. A judge is considered trustworthy only when its evaluations consistently align with the PM’s "taste." Until this alignment is reached, the judge’s output should be treated as a suggestion rather than an absolute metric.

The ninth step involves connecting evaluation quality to real-world performance. A successful AI feature should show a correlation between three key metrics: the quality score of the evaluation dataset, the quality observed during internal "dogfooding," and the quality reported by external users. If these numbers diverge—for example, if evaluation scores are high but internal feedback is poor—it indicates that the evaluation dataset does not accurately reflect how users are actually interacting with the tool. This mismatch requires a reassessment of the dataset and the rules governing the AI’s behavior.
Finally, the framework emphasizes that AI quality is a "team sport." While the PM may drive the vision of quality, the entire team—including engineers, designers, and data scientists—must be involved in the evaluation process. This includes collaborative "bug bashes," shared reviews of AI judge results, and collective decision-making on model trade-offs.
In summary, shipping a high-quality AI feature requires a shift from anecdotal validation to a structured system of rules, evolving datasets, and scalable evaluation loops. By anchoring development in a clear "why," maintaining a rigorous "single source of truth" for data, and scaling human judgment through validated AI judges, product teams can move beyond the uncertainty of "vibes." The ultimate goal is to reach a state where the evidence—derived from evals, judges, and real-world usage—clearly supports the conclusion that the feature is ready for the rigors of a professional environment. As AI continues to exhibit "weird and wonderful" behaviors in edge cases, these structured processes ensure that those surprises lead to learning and improvement rather than product failure.